
Diffusion models have demonstrated impressive capabilities in image generation and have been effectively adapted for image restoration tasks. However, despite their success, diffusion models often struggle to generate images with sufficient detail, particularly in complex scenarios. This limitation becomes more pronounced in image restoration, where the goal is to recover fine details from degraded inputs. To address this challenge, we propose Diff-Plugin, a training-free method that leverages the generation capability of pre-trained diffusion models for low-level tasks while incorporating a plugin module to enhance detail generation. Our approach utilizes a lightweight plugin trained specifically on pairs of low-quality and high-quality images to refine the outputs of diffusion models. The plugin is designed to revitalize the details that diffusion models may overlook, thereby improving the overall quality of restored images. Extensive experiments on various image restoration tasks, including denoising, deblurring, super-resolution, and deraining, demonstrate the effectiveness of our method in enhancing detail recovery while maintaining the advantageous properties of diffusion models.

Overview of our Diff-Plugin framework. We leverage pre-trained diffusion models and introduce a lightweight plugin network to enhance detail generation for low-level vision tasks.

Comparison results on image denoising tasks. Our method achieves superior detail recovery compared to existing approaches.

Face restoration results showing improved detail preservation and natural-looking outputs.
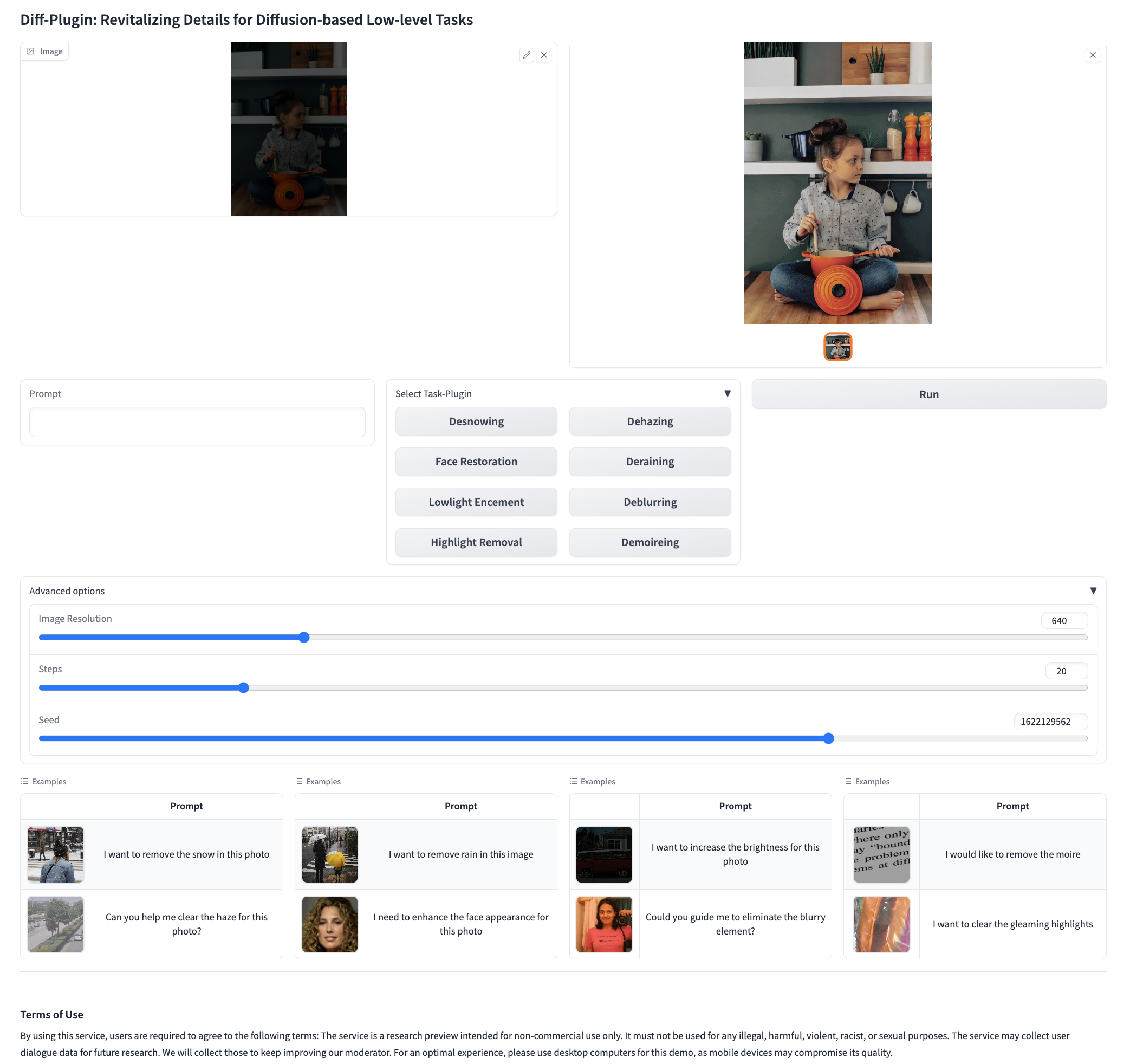
Our interactive Gradio demo allows users to test different low-level vision tasks with natural language instructions.
Demonstration video showing the capabilities of Diff-Plugin across various low-level vision tasks.
@inproceedings{liu2024diffplugin,
title={Diff-Plugin: Revitalizing Details for Diffusion-based Low-level Tasks},
author={Liu, Yuhao and Ke, Zhanghan and Liu, Fang and Zhao, Nanxuan and Lau, Rynson W.H.},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}